The Third Time's the Package: Extracting a Go Image Generation Library
Three projects, three copy-pasted image pipelines, one inevitable extraction. Building imagen — a reusable Go library for multi-provider AI image generation with automatic GCS upload — taught me when to generalize, when to copy, and why the third time is the threshold.

The Sinking Feeling
It was a Tuesday afternoon. I was staring at my editor, writing the same HTTP handler for the third time.
A POST endpoint. Read an API key from an environment variable. Build a JSON body with a text prompt. Call an AI image generation API. Parse a base64 response. Upload the decoded bytes to Google Cloud Storage. Return a URL.
I had already written this exact pipeline twice before — once in storyclub/agent/internal/gpt/ and once in illustra-go/tools/stability_ai.go. Each time it was slightly different. Different retry logic. Different error handling. Different config loading. Different GCS upload paths.
The third time wasn't a new project. It was me, realizing that I'd already written this three times, and wondering how many more copies were scattered across my repos.
That's when I decided to extract it into a proper Go library: imagen — a unified, multi-provider AI image generation package with automatic cloud storage upload.
This is the story of that extraction, the design decisions along the way, and what I learned about when a copy-paste stops being "faster" and starts being tech debt.
The Three Pipelines
Before the extraction, there were three separate implementations of the same fundamental pipeline:
Three files, three different approaches to every single concern.
Retry divergence
The storyclub agent implemented inline retry with exponential backoff: attempt up to 5 times, sleep (attempt^2) * 100ms between attempts, capped at 30 seconds.
The illustra-go tool had no retry at all. If the Stability API returned a 429, the request failed and the caller got an error.
The storyclub vision package had a doPostWithRetry wrapper that lived in the same file as the Stability handler — not reusable, not testable, and tightly coupled to HTTP requests.
Config divergence
Each project loaded configuration differently:
# storyclub/agent — spread across 3 files
OPENAI_API_KEY=sk-...
GCS_BUCKET_NAME=my-bucket
# illustra-go — ad-hoc os.Getenv calls
STABILITY_KEY=...
GCS_BUCKET_NAME=my-bucket
# storyclub/vision — config struct
STABILITY_API_KEY=...
STABILITY_ENDPOINT=https://api.stability.ai/v1
STABILITY_MODEL=stable-diffusion-xl-1024-v1-0
GCS_BUCKET=my-bucket
GCS_IMAGE_PREFIX=images/Same fundamental need, three different env var names, three different loading strategies. This meant every new project required spelunking through old code to figure out which env vars to set.
GCS upload divergence
The storage layer was the worst offender. One project used Firebase Storage download tokens, another used direct GCS public URLs, a third used signed URLs. The object path conventions were different in each:
storyclub: gcs://bucket/images/{uuid}.png
illustra: gcs://bucket/{uuid}.png
vision: gcs://bucket/{prefix}/stability/{uuid}.webpThese aren't just cosmetic differences. Each convention baked in assumptions about CDN configuration, access control, and URL expiration that were invisible to anyone copying the code.
The Threshold
There's a rule of thumb in software engineering about extraction: do it once, copy it. Do it twice, tolerate the duplication. Do it three times, extract.
The third time is the threshold because:
1. You now have enough data points to know which parts are truly generic and which are project-specific
2. The cost of maintaining three diverging copies exceeds the cost of designing an abstraction
3. The next project that needs this pipeline won't have to make the same mistakes
I was firmly past the threshold. Time to extract.
The Extraction Process
I started by defining the core interfaces — the contract that every provider and storage backend would need to fulfill.
Step 1: The Provider Interface
type Provider interface {
Generate(ctx context.Context, req *Request) (*Result, error)
}
type Request struct {
Prompt string
Model string
Size string
Quality string
N int
Style string
Extras map[string]any
}
type Result struct {
Data []byte
ContentType string
Seed int
Prompt string
Provider ProviderID
CreatedAt time.Time
}The Result type uses raw []byte for image data. This was a deliberate choice over interfaces like io.Reader or streaming — image generation APIs return base64 strings or URLs, both of which resolve to a blob of bytes. Exposing []byte is the simplest thing that works, and simplicity wins in a library meant to be copy-pasted into any project.
Step 2: The Storage Interface
type Storage interface {
Upload(ctx context.Context, result *Result) (*StorageResult, error)
}
type StorageResult struct {
URL string
Bucket string
ObjectPath string
ContentType string
Size int64
CreatedAt time.Time
}Storage is decoupled from generation. This means you can swap GCS for S3, Azure Blob, or a local filesystem without touching your image generation code. And you can test generation without worrying about cloud credentials.
Step 3: The Client
type Client struct {
provider Provider
storage Storage
}
func (c *Client) GenerateAndStore(ctx context.Context, req *Request) (*StorageResult, error) {
result, err := c.provider.Generate(ctx, req)
if err != nil {
return nil, fmt.Errorf("generate: %w", err)
}
storageResult, err := c.storage.Upload(ctx, result)
if err != nil {
return nil, fmt.Errorf("store: %w", err)
}
return storageResult, nil
}Twelve lines of code. That's the entire orchestration layer. The simplicity is intentional — GenerateAndStore is the 80% use case, and it should be immediately obvious what it does.
Step 4: The OpenAI Provider
The first provider I extracted was OpenAI's image generation API. The source code lived in storyclub/agent/internal/gpt/ — a private package tightly coupled to the agent's config system.
Extracting it meant:
1. Replacing hardcoded config references with functional options:
type OpenAIOption func(*OpenAIProvider)
func NewOpenAIProvider(apiKey string, opts ...OpenAIOption) *OpenAIProvider {
p := &OpenAIProvider{
apiKey: apiKey,
model: "gpt-image-2",
size: "1024x1024",
quality: "standard",
client: &http.Client{Timeout: 90 * time.Second},
maxRespSize: 50 << 20,
}
for _, opt := range opts {
opt(p)
}
return p
}Functional options are the idiomatic Go pattern for optional configuration. They're discoverable in autocomplete, composable, and backward-compatible when you add new options.
2. Adding better response parsing:
The original handler only handled b64_json responses. The extracted version handles both b64_json and url:
switch {
case img.B64JSON != "":
imgData, err = base64.StdEncoding.DecodeString(img.B64JSON)
case img.URL != "":
imgData, err = p.downloadImage(ctx, img.URL)
}3. Magic-byte content-type detection:
Instead of trusting the provider's declared content type, I detect it from the first bytes of the image data:
func detectContentType(data []byte) string {
switch {
case len(data) > 8 && string(data[:8]) == "\x89PNG\r\n\x1a\n":
return "image/png"
case len(data) > 2 && data[0] == 0xFF && data[1] == 0xD8:
return "image/jpeg"
case len(data) > 4 && string(data[:4]) == "RIFF" && string(data[8:12]) == "WEBP":
return "image/webp"
default:
return "image/png"
}
}This matters because different providers return different formats, and the same provider can return different formats for different prompts. Magic-byte detection is the only reliable approach.
Step 5: The GCS Storage Backend
The GCS storage backend was extracted from storyclub/agent/internal/tools/storage/gcs.go. The original had Firebase Storage download token logic, hardcoded object paths, and no public URL customization.
The extracted version made all of these configurable:
func NewGCSStorage(bucket string, opts ...GCSOption) *GCSStorage {
s := &GCSStorage{
bucket: bucket,
objectNamer: defaultObjectNamer,
publicURL: defaultFirebaseURL,
}
for _, opt := range opts {
opt(s)
}
return s
}The objectNamer function lets users control the GCS object path. The publicURL function lets them choose between Firebase Storage URLs, direct GCS URLs, or custom CDN domains.
Step 6: The Generic Retry Utility
One of the most useful byproducts of the extraction was a standalone generic retry utility:
func RetryDo[T any](ctx context.Context, cfg RetryConfig, fn func(context.Context) (T, error)) (T, error)The generics (T any) mean you can use it for any operation, not just HTTP requests:
result, err := RetryDo(ctx, RetryConfig{
MaxRetries: 3,
BaseDelay: 1 * time.Second,
MaxDelay: 30 * time.Second,
}, func(ctx context.Context) (string, error) {
return myFlakyOperation(ctx)
})It features exponential backoff with jitter, context cancellation, and a configurable ShouldRetry predicate. Nine unit tests verify the behavior — something the original inline retry never had.
Step 7: The Config System
The config system was designed last, after I understood what every provider and storage backend needed:
type Config struct {
OpenAIAPIKey string
StabilityAPIKey string
GCSBucket string
GCSObjectPrefix string
Model string
Size string
Quality string
Provider ProviderID
MaxRetries int
BaseDelay time.Duration
MaxDelay time.Duration
HTTPTimeout time.Duration
MaxResponseSize int64
MaxImageSize int64
StabilityEndpoint string
StabilityModel string
StabilityCfgScale float64
StabilitySteps int
StabilityStylePreset string
OutputFormat string
}The crown jewel is LoadConfigFromEnv:
func LoadConfigFromEnv() Config {
if _, err := os.Stat(".env"); err == nil {
godotenv.Load()
}
// ... read every env var
}It auto-loads .env files if they exist (safe for development) but silently skips them in production environments like Cloud Run where env vars come from the platform. This one function eliminated the most common "why isn't my config loading?" debugging session.
The Design Decisions (The Twist)
Extracting a package isn't just about moving code around. Every decision reveals assumptions you made in the original implementations. Here are the ones that surprised me:
Flat vs. `internal/` Package
My first instinct was to put providers and storage backends in an internal/ subdirectory:
imagen/
├── internal/
│ ├── openai/
│ │ └── provider.go
│ └── gcs/
│ └── storage.go
├── imagen.go
└── config.goThis broke immediately. The factory functions in imagen.go needed to import the providers, but the providers needed to import core types from imagen.go. Circular import.
The fix was flatter:
imagen/
├── imagen.go — Core types, interfaces, Client, NewClientFromConfig
├── openai.go — OpenAI provider (same package)
├── stability.go — Stability AI provider (same package)
├── gcs.go — GCS storage (same package)
├── config.go — Config, options, env loading
├── errors.go — Sentinel errors
└── retry.go — Generic retry utilityEverything in package imagen. No circular imports, no internal/ hierarchy to navigate. The trade-off is that all provider implementations are exported from the root package, but for a focused library like this, that's fine — you're not hiding implementation details, you're exposing capabilities.
The `gpt-image-2` Response Format
When I extracted the OpenAI provider, I hit an immediate problem. The original code used response_format: "b64_json". But gpt-image-2 (the default model) rejects the response_format parameter:
Error: parameter 'response_format' is not supported by this modelThis was silently working in the original code because the response format defaulted to b64_json anyway — the parameter was redundant. But I discovered this only when testing the extracted version and getting a 400 error.
The fix was to default to an empty response_format string and only set it if explicitly configured. This was a bug hiding in plain sight — the original code had a parameter that did nothing but would have broken if anyone tried to set it to "url".
The 50MB Response Limit
The original OpenAI implementation had maxRespSize: 2 << 20 (2MB). This worked during testing because the test images were small.
In production, gpt-image-2 can return base64-encoded images over 10MB in their JSON-wrapped response. The base64 encoding adds 33% overhead, and the JSON wrapper adds framing. A 5MB raw image becomes ~7MB of JSON. A 2MB limit would silently truncate the response.
I bumped it to 50 << 20 (50MB). This is more than enough for any current image model, but the error message when hit tells users exactly what to increase:
response truncated at 52428800 bytes, increase max response sizeFirebase Storage URLs
The original GCS upload code used Firebase Storage download tokens for URL access. These are opaque tokens that Firebase generates, used for authenticated downloads through the Firebase SDK.
The extracted version keeps Firebase URLs as the default but makes it configurable via WithGCSPublicURL. The EnsureFirebaseToken helper is also exposed for cases where you need to add a token to an existing object.
Auto-loading `.env` in Serverless
The trickiest design decision was whether to auto-load .env files. On one hand, developers expect .env to "just work" in local development. On the other hand, godotenv.Load() silently fails in Cloud Run (no .env exists), and you don't want the package to panic.
The solution: guard the load with an os.Stat check:
if _, err := os.Stat(".env"); err == nil {
godotenv.Load()
}No error if .env is missing. .env is loaded if present. This is safe in both development and production.
Architecture
Here's the final architecture:
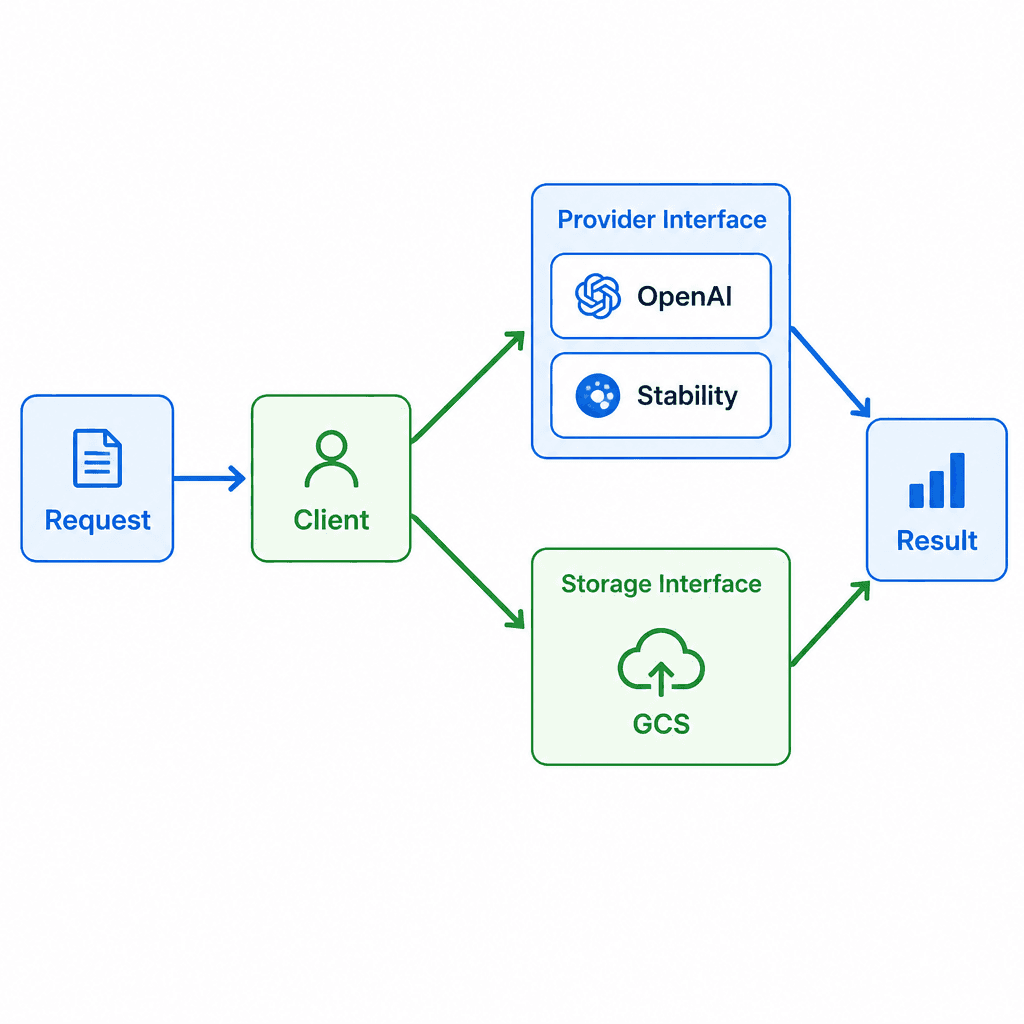
The flow is straightforward:
1. Caller creates a Request with a prompt
2. Client.GenerateAndStore calls the Provider to generate an image
3. The same method calls Storage.Upload to persist the result
4. Returns a StorageResult with the public URL
The separation between Provider and Storage means you can swap either independently. Want to use Stability instead of OpenAI? Change the provider. Want local files instead of GCS? Swap the storage backend. The Client orchestrator doesn't know or care.
The Extraction Decision Tree
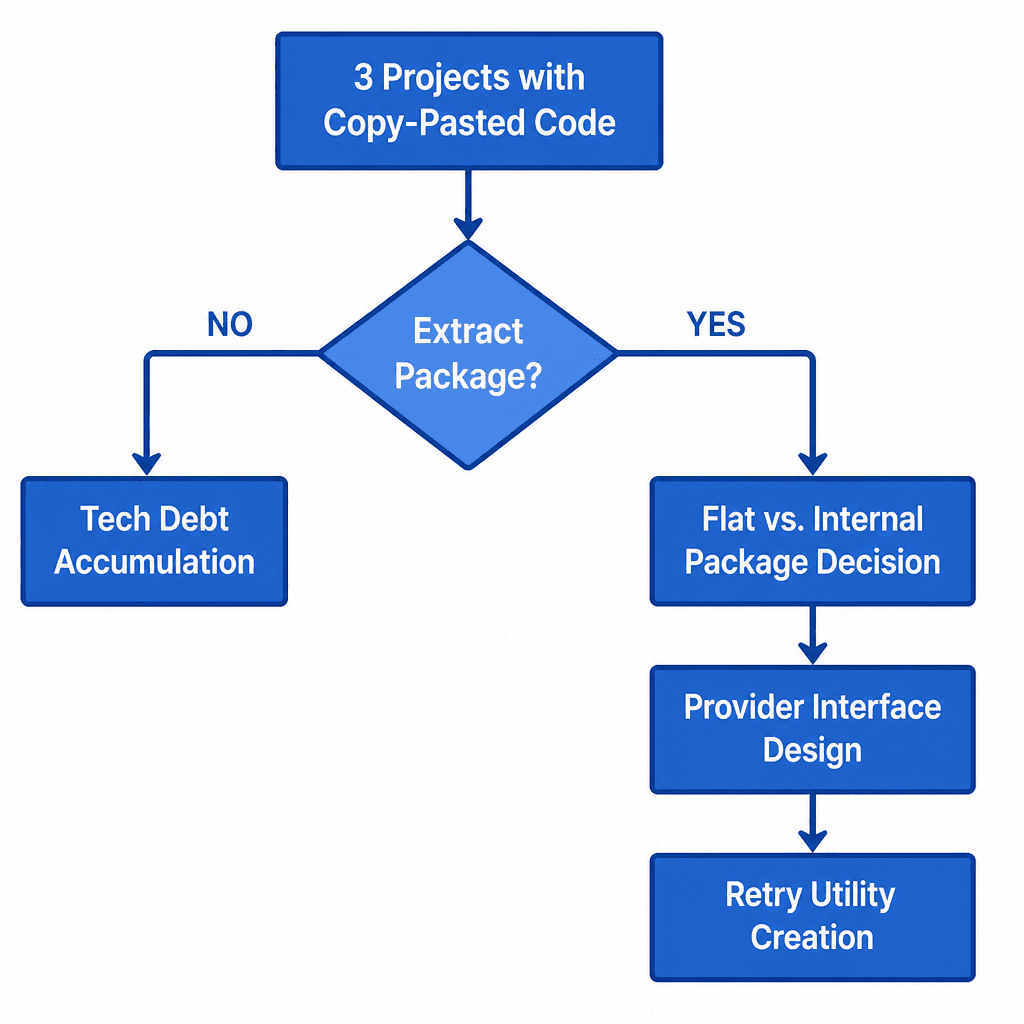
The extraction process itself is a decision tree:
LoadConfigFromEnv, per-provider via functional options.RetryDo[T] works for anything.The Final Package
After the extraction, the imagen package weighs in at:
Client, Config, Request, Result, StorageResult)Provider, Storage)ErrAPIKeyRequired, ErrContentFiltered, etc.)RetryDo[T])Using It
The end result is remarkably simple to use:
package main
import (
"context"
"fmt"
"log"
"github.com/mnkrana/imagen"
)
func main() {
cfg := imagen.LoadConfigFromEnv()
client, err := imagen.NewClientFromConfig(cfg)
if err != nil {
log.Fatalf("client: %v", err)
}
result, err := client.GenerateAndStore(context.Background(), &imagen.Request{
Prompt: "a serene mountain landscape at sunset, photorealistic",
})
if err != nil {
log.Fatalf("generate: %v", err)
}
fmt.Printf("URL: %s\n", result.URL)
fmt.Printf("Size: %d bytes\n", result.Size)
}That's it. Twenty lines of code, including imports. The .env file handles the rest:
IMAGEN_PROVIDER=openai
OPENAI_API_KEY=sk-...
GCS_BUCKET=my-image-bucketWhat I Learned
1. The third time is the threshold
First time: you're learning the API. The code is scrappy, coupled to the specific use case, and probably lives inline in a handler somewhere.
Second time: you know the pattern, so you copy the scrappy code and make it work for the new project. You notice the duplication but fixing it feels like more work than just getting it done.
Third time: the duplication is now the most expensive part of the system. Every bug fix, every feature addition, every new provider integration has to be done N times. Extraction is no longer optional.
2. Extraction reveals assumptions you didn't know you had
Until I extracted the OpenAI provider, I didn't know gpt-image-2 rejects the response_format parameter. Until I extracted the GCS storage, I didn't know the Firebase URL format was project-specific. Every extraction surfaces assumptions that were invisible when the code was embedded in a single project.
3. Generic utilities are better as byproducts
The RetryDo[T] generic was a byproduct of extracting the retry logic from the OpenAI provider. I didn't set out to build a generic retry library — I set out to extract a retry function, and generics made it naturally reusable. This is the right way to build generic utilities: extract them from real use cases, not from theory.
4. Simplicity wins in libraries
The entire Client is 12 lines of code. There's no middleware stack, no plugin system, no event hooks. There's a Provider interface, a Storage interface, and a method that calls them in sequence.
A library that tries to handle every edge case handles none well. A library that solves one problem cleanly gets used.
5. Documentation is not optional
I spent as much time on the README as on any single source file. The architecture diagram, the quick start, the config table, the error handling guide — these are what make a library usable by someone who didn't live through the extraction process.
What's Next
The package is in active use. The immediate roadmap:
illustra-go project, same Provider interfacelog.Printf with slogThe Takeaway
Copy-pasting code is not always wrong. In fact, it's often the right call — for the first two uses. You don't have enough information to build a good abstraction until you've seen the pattern play out in at least two different contexts.
But the third time? That's the signal. When you find yourself making the same edit in three different files, stop. Extract. The hours you spend designing the abstraction will be paid back the first time a new project imports your package instead of writing another copy.
The repo is at github.com/mnkrana/imagen. The code is MIT-licensed. If you've written the same image generation pipeline three times, it might save you from writing it a fourth.
Images generated with OpenAI via the Illustra agent. Architecture and flow diagrams use the [openai] prefix for accurate text rendering.