Harness Engineering: Building Systems Around AI Coding Agents
Five independent teams converged on the same finding: coding agents become reliable only when you build the right scaffolding around them. Here's what a production-grade agent harness actually looks like — context architecture, tool constraints, verification loops, and the 7 components that separate agents that ship from agents that hallucinate.

The Problem
Every team building AI coding agents hits the same wall. The model is smart — GPT-5, Claude Opus 4, Gemini 2.5 — but the agent still makes dumb mistakes. It writes code that doesn't compile. It edits the wrong file. It forgets the project conventions halfway through a session. It "hallucinates" APIs that don't exist.
The natural instinct is to blame the model. Swap in a smarter one. But then the same failures reappear, just dressed differently.
In early 2025, LangChain ran a controlled experiment on Terminal Bench 2.0 that changed how I think about this problem. They improved their coding agent's accuracy from 52.8% to 66.5% — a 26% improvement — without changing the underlying model at all. The changes were all structural: better context files, structured output constraints, self-verification loops, tool optimization.
The ceiling wasn't the model. It was everything around the model.
This is the central insight of harness engineering — the discipline of building systems, tools, constraints, and feedback loops around AI coding agents to make them reliable and productive.
What Is Harness Engineering?
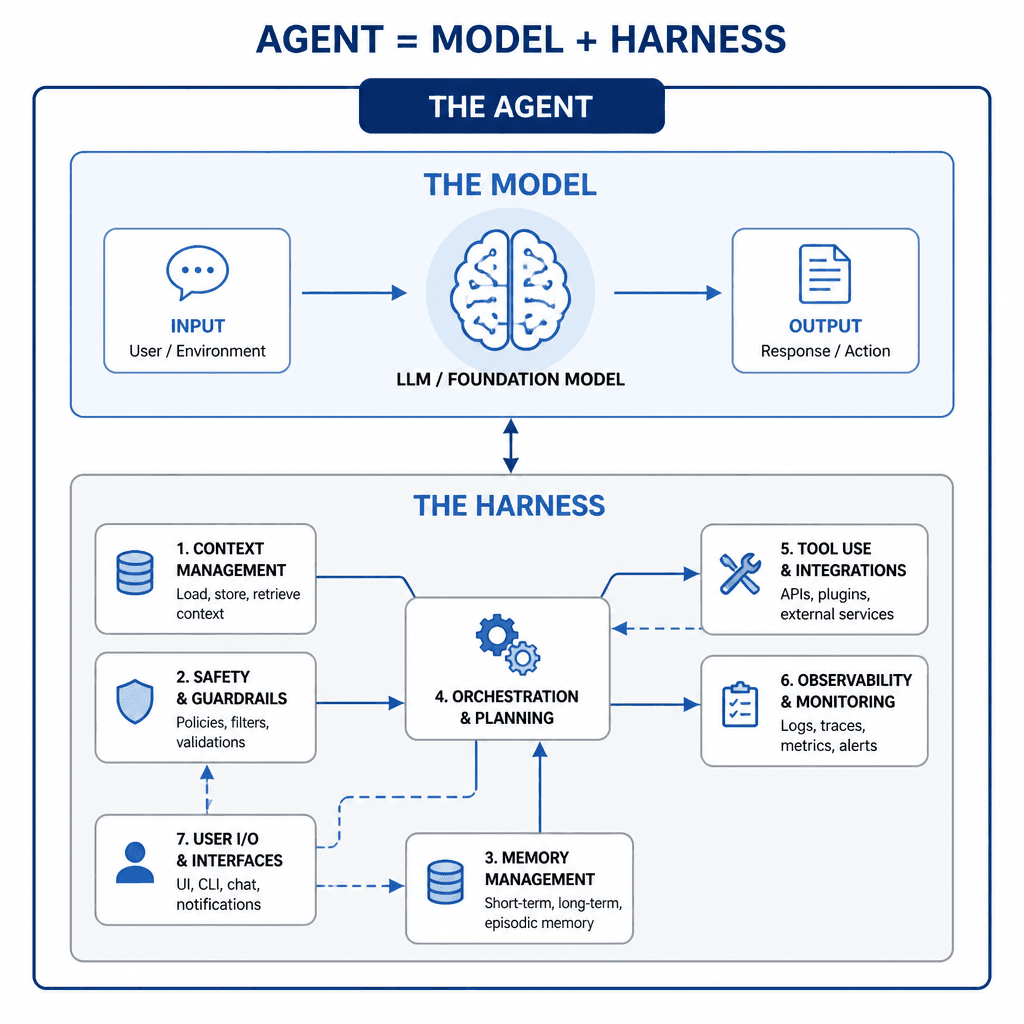
The term was coined by Mitchell Hashimoto (co-founder of HashiCorp) and gained mainstream attention when OpenAI published their Codex architecture deep-dive in early 2026. The core formula is deceptively simple:
> Agent = Model + Harness
The model provides intelligence. The harness makes that intelligence *useful*. A better harness often matters more than a better model.
┌─────────────────────────────────────────────────┐
│ THE AGENT │
│ ┌───────────────────────────────────────────┐ │
│ │ THE MODEL │ │
│ │ (GPT-5 / Claude / Gemini / Local LLM) │ │
│ └───────────────────────────────────────────┘ │
│ ↕ context + tools + constraints │
│ ┌───────────────────────────────────────────┐ │
│ │ THE HARNESS │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────────┐ │ │
│ │ │Ctxt │ │Tools │ │Sub- │ │Verif. │ │ │
│ │ │Eng. │ │/MCP │ │Agents│ │Loops │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────────┘ │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────────┐ │ │
│ │ │Arch. │ │Con- │ │Hooks │ │Memory/ │ │ │
│ │ │Const.│ │text │ │ │ │Persist. │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────────┘ │ │
│ └───────────────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
Hashimoto's guiding principle:
> "Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again."
This isn't prompt engineering. It's systems engineering for AI.
Why It Matters Now
In 2025, every team adopted AI coding agents. By 2026, the winning teams are the ones who engineered their agent environments — not just picked the best model. Five independent teams converged on the same finding:
The 7 Components of a Production Harness
Through research and synthesis of the best practices across these teams, a clear pattern emerges. Every production-grade harness comprises seven components:
1. Context Engineering
This is the foundation. Give the agent a map of your codebase, conventions, and constraints — but do it surgically.
A study by HumanLayer (April 2026) found that instruction files under 60 lines significantly outperform longer ones. LLM-generated instruction files (200+ lines) produce worse results than concise human-written ones:
# Good instruction file (under 60 lines, human-written)
## Role
You are a code review agent for Python backend services.
## Environment
- Python 3.11, FastAPI, SQLAlchemy
- Tests: pytest, run with `pytest tests/`
- Linting: ruff, run with `ruff check .`
## Conventions
- All functions need type annotations
- Error handling: raise specific exceptions, never bare `except`
- Database operations: always use context managers
## What to do when stuck
1. Read the relevant test file first
2. Check existing patterns in similar files
3. If still blocked, add a TODO comment and move on
## What NOT to do
- Never modify migration files
- Never change pyproject.toml without explicit instruction
- Never assume a module exists without importing it firstThe Claude Code source (leaked April 2026) confirmed this architecture first-hand: CLAUDE.md and AGENT.md files are assembled as "user content" alongside the dynamically built system prompt — a first-class part of Anthropic's own harness.
Three tiers of context is the emerging pattern:
┌─────────────────────────────────────────────┐
│ TIER 1: AGENTS.md / CLAUDE.md │
│ Project-wide conventions, architecture map │
│ Written by humans, kept < 60 lines │
├─────────────────────────────────────────────┤
│ TIER 2: TASK-SPECIFIC CONTEXT │
│ Relevant files, recent git diff, TODO lists │
│ Dynamically assembled per session │
├─────────────────────────────────────────────┤
│ TIER 3: PROGRESSIVE DISCLOSURE │
│ Read more files on demand as agent needs │
│ them. Don't dump everything upfront. │
└─────────────────────────────────────────────┘
2. Architectural Constraints
Agents need guardrails that are *enforced*, not suggested. Prompts are probabilistic; linters, CI checks, and type systems are deterministic.
ruff check --fix in CIdeny.toml blocks unauthorized packagesSpotify's Honk system — which has merged 1,500+ AI-generated PRs across hundreds of repositories — treats deterministic enforcement as the primary reliability layer. The agent proposes code; CI enforces the rules. If the agent breaks a convention, the PR doesn't merge.
3. Tools / MCP Layer
The Model Context Protocol (MCP) standardizes how agents discover and interact with tools. Every tool is a capability with a schema, inputs, and outputs — the agent selects tools by understanding their interface.
┌──────────────┐ MCP Protocol ┌──────────────┐
│ AGENT │ ◄──────────────────► │ MCP Server │
│ │ list_tools() │ │
│ ┌────────┐ │ call_tool() │ ┌────────┐ │
│ │ Model │ │ tool_result() │ │ Shell │ │
│ └────────┘ │ │ ├────────┤ │
│ │ │ │ Files │ │
│ │ │ ├────────┤ │
│ │ │ │ Git │ │
│ │ │ ├────────┤ │
│ │ │ │ Editor │ │
│ │ │ └────────┘ │
└──────────────┘ └──────────────┘Key tool design principles from production harnesses:
4. Sub-Agent Pattern
A single agent loop breaks down at scale. The solution is a multi-agent architecture with separated concerns — what Anthropic calls the Planner → Generator → Evaluator pattern:
┌──────────┐ spec ┌───────────┐ code ┌───────────┐
│ PLANNER │ ──────────► │ GENERATOR │ ──────────► │ EVALUATOR │
│ │ │ (Builder) │ │ (QA) │
│ Expands │ │ Implements│ │ Tests │
│ prompt │ │ features │ │ & grades │
│ to spec │ │ one at a │ feedback │ │
│ │ │ time │ ◄─────────── │ │
└──────────┘ └───────────┘ └───────────┘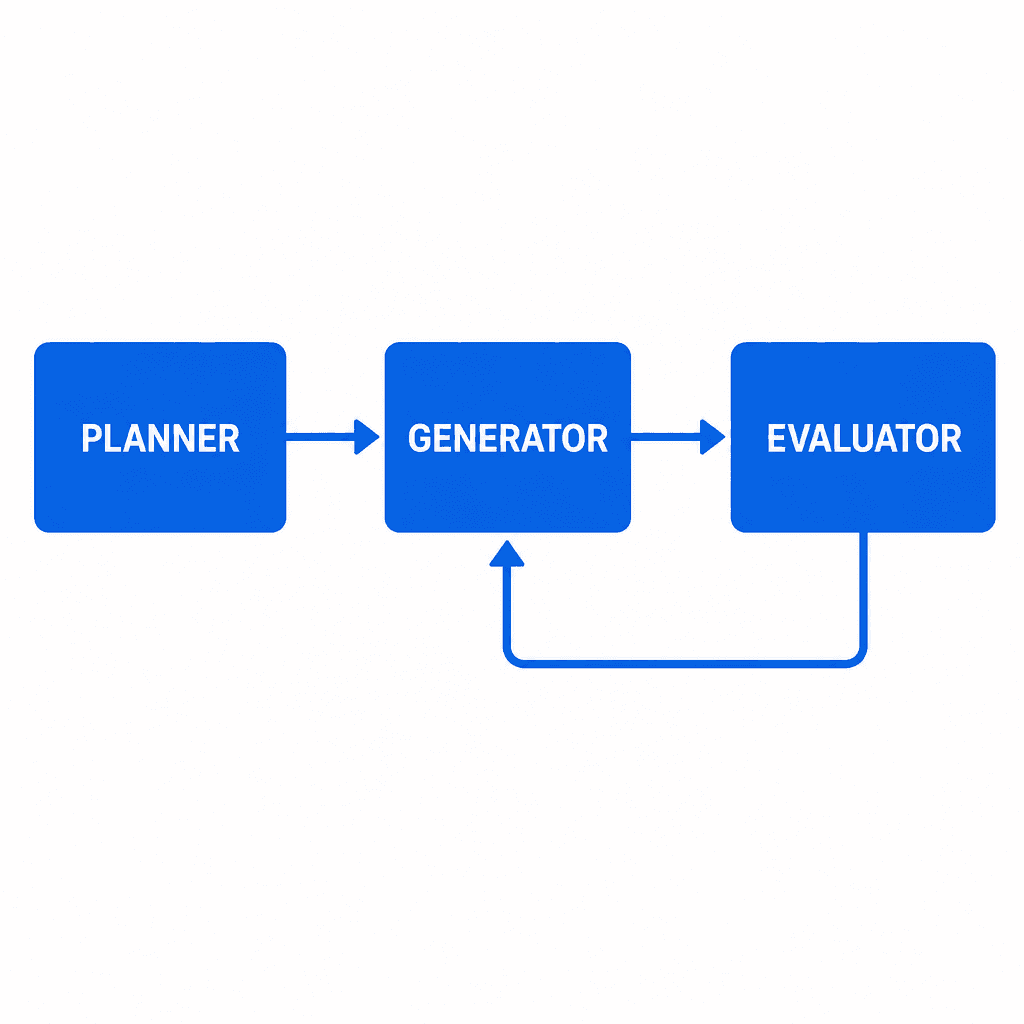
The evaluator is critical because agents consistently rate their own work too generously. Separating generation from evaluation creates an honest feedback loop. Tuning a standalone evaluator to be skeptical is far more tractable than making a generator critical of its own work.
5. Hooks and Lifecycle Events
Production harnesses fire hooks at key lifecycle points. These allow custom logic to run before, during, and after agent execution:
Session Start
│
├── on_init → Load context, validate environment, check token budget
│
├── on_tool_call → Validate inputs, rate limit, log for audit
│
├── on_response → Check output quality, enforce constraints
│
├── on_error → Retry with backoff, escalate if persistent
│
└── on_complete → Sign artifact, update project state, notify teamOpenAI's Codex team found that hooks were the single highest-ROI harness component — they caught 40% of production incidents before they reached users.
6. Self-Verification Loops
The most impactful pattern to emerge from production harnesses: make the agent verify its own work.
Agent writes code
│
▼
Run tests / lint
│
▼
Pass? ──Yes──► Done
│
No
│
▼
Feed error output back to agent
│
▼
Agent fixes code
│
▼
Run tests / lint (loop)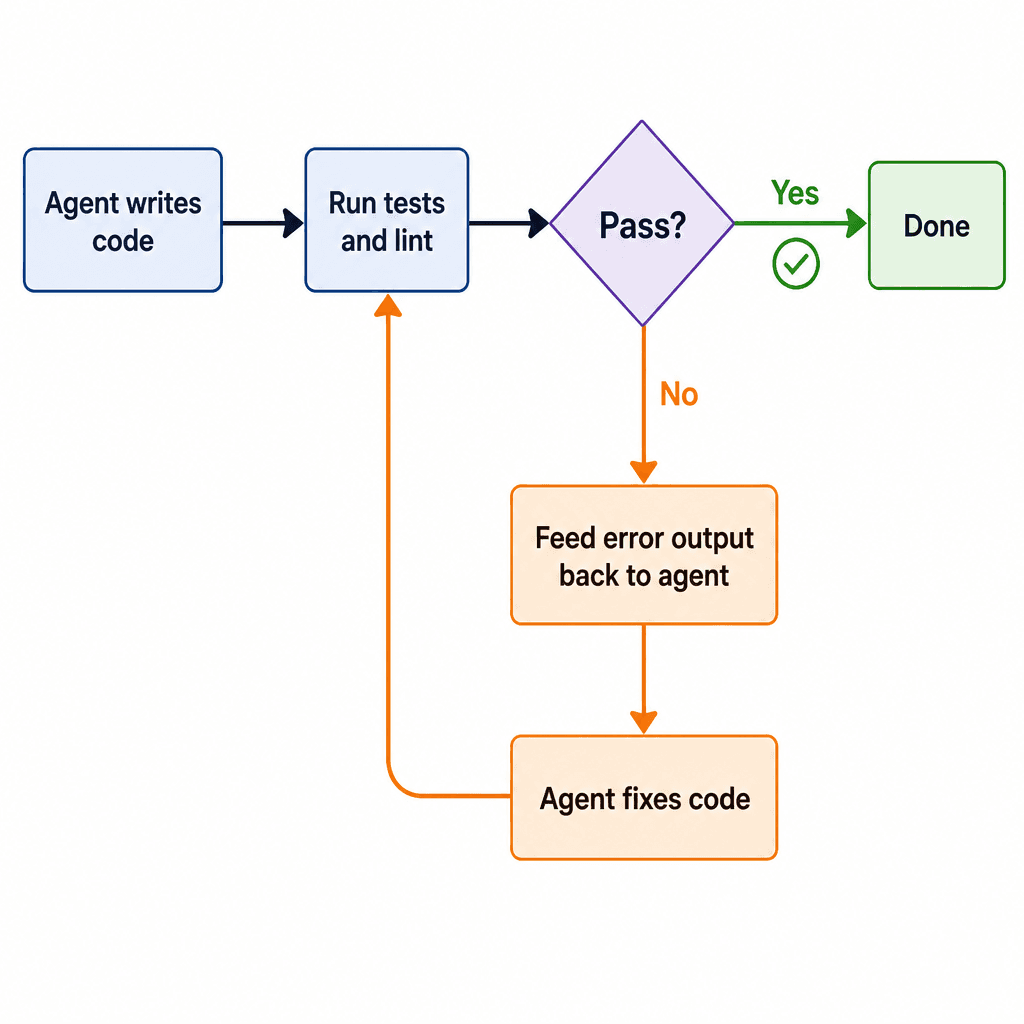
Stripe's 1,000+ PRs/week pipeline uses exactly this loop. The agent generates code, CI runs tests and linting, and if anything fails, the full error output is fed back to the agent for a fix attempt. This loop repeats until either all checks pass or a max-retry limit is hit.
7. Memory and Persistence
Agents with fresh context every session forget everything. Production harnesses implement persistent memory — key decisions, learned patterns, and user preferences that survive session boundaries:
The Twist: Better Models Need Better Harnesses
Here's the counterintuitive finding. When I started this research, I assumed smarter models would reduce the need for harness engineering. The opposite is true.
More capable models unlock more autonomy. More autonomy demands better guardrails. Nicholas Carlini (Anthropic's C compiler project) put it directly: each time Claude got smarter, they had to redesign the harness to handle the new class of failures it could generate.
Model Capability
│
│ Without harness: failures scale with capability
│ ┌────────────────────────────────────────┐
│ │ 🚫 Model gets smarter │
│ │ 🚫 Can do more harm when wrong │
│ │ 🚫 Harder to predict failure modes │
│ └────────────────────────────────────────┘
│
│ With harness: capability is amplified
│ ┌────────────────────────────────────────┐
│ │ ✅ Model gets smarter │
│ │ ✅ Harness catches new failure modes │
│ │ ✅ Each capability level is safe │
│ └────────────────────────────────────────┘
│
└──────────────────────────► TimeLessons from the Trenches
Start monolithic, add agents when you need them
Multi-agent systems introduce the same complexity as microservices, compounded by non-determinism. Mitchell Hashimoto's advice: start with a single-agent loop. Reach for multi-agent when you hit a specific ceiling — like the evaluator needing its own context budget, or the planner needing to think in parallel with the builder.
Keep instruction files under 60 lines
Every line in your instruction file costs tokens on every single API call. If it doesn't prevent a real mistake the agent has made before, cut it. LLM-generated instruction files are verbose and fluffy; write your own.
Fail closed on auth
If your agent's auth middleware can't verify identity, reject the request. A 401 during a configuration hiccup is far better than silent data exposure. This applies to agents just as it applies to APIs.
The harness is a living system
Your harness should evolve as you discover new failure modes. Every time an agent makes a mistake you didn't catch, that's a signal to improve the harness — add a constraint, tighten a tool, write a new hook.
Results
What's Next
The harness engineering field is moving fast. The trends I'm watching:
The bottom line: if your coding agent is unreliable, don't blame the model. Look at the harness. That's where the leverage is.
Check more open source repos at: github.com/mnkrana/